|
|
|
|
|
|
|
|
|
|
|
|
|
|
 |
 |
 |
 |
 |
 |
 |
 |
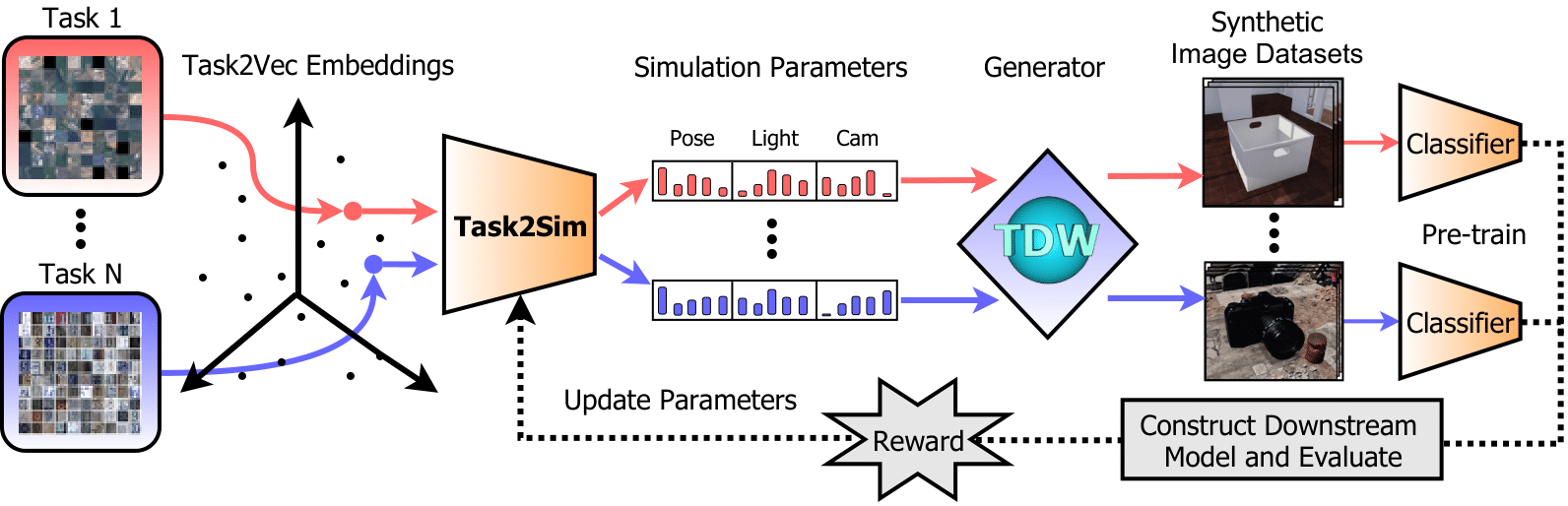
Different properties of synthetic data parameterized in simulation
|
|
Samarth Mishra, Rameswar Panda, Cheng Perng Phoo, Chun-Fu Chen, Leonid Karlinsky, Kate Saenko, Venkatesh Saligrama, Rogerio Feris Task2Sim: Towards Effective Pre-training and Transfer from Synthetic Data [Arxiv] [Code] [Poster] [Video] |